昨年11月末に、初のゲームタイトルとなるソーシャルゲーム「AFRER FIRE Re」をリリースし、運用するなかでの気づきを備忘録も兼ねて。
急激なロードアベレージの上昇と謎のstealなる値
イベント終了の3時間後に新イベントを開始。イベント開始の後しばらくすると、CPU使用率が100%あたりまで上昇するもゲーム自体は快適にプレイできており、まったく問題なし。
しばらくの後、運営チームからゲームが重いし、エラーが出始めると報告をうけ、状況を確認すると、ロードアベレージが急激に高くなり、なぞのstealなる値もあわせて急激に増加。。。
stealってなに?
ざっくり言うと「CPUリソースを割り当ててもらえなかった時間の割合」との事。つまり、処理をしたいのに出来ていない状態が発生しているという状況。
t2.mediumを使っているので、vCPUは2コア。まだ余力があるはずと思っていましたが、T2インスタンスについて大きな思い違いがありました。
詳細は割愛しますが、要するに「CPU負荷が高い状態を長くは続けられない」インスタンスタイプで、ある程度のCPU使用率を超えると、CPUクレジットを消費し、使い切った場合には最低限(t2.mediumは2CPU合計で40%)のパフォーマンスしか提供しないと。
T2インスタンスの詳細について
http://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/t2-instances.html
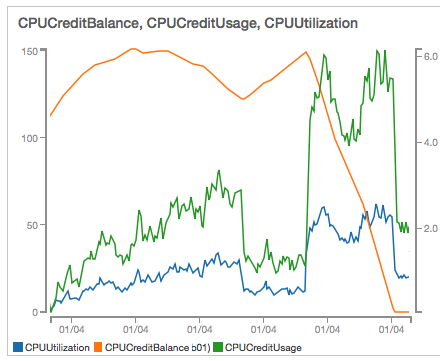
Cloud Watchのグラフをみると、確かに説明の通りで、CPU使用率が一定値を超えるとクレジットが消化されていき、残ゼロになったタイミングで制限が掛かっています。
対処方法
サーバー(インスタンス)を再起動する
インスタンスを再起動する事で、起動時のクレジット付与が発生し、一時的ではありますが状況が改善します。
インスタンスを増やす(スケールアウト)
台数が増えるという事は、当然ながら面倒を見なければならない事や場所が増えるので、何らかの際に手間が増えるのが難点です。
インスタンスタイプを上位に変更する(スケールアップ)
初期CPUクレジットが多く、時間当たりに付与されるCPUクレジットも多いので台数を増やすよりは安易に実行しやすいです。
CPUクレジット方式ではない(T2以外の)インスタンスに変更する
ある意味スケールアップではありますが、定常的に負荷がかかる様な場合で、コストの兼ね合いがとれればこちらの方が確実ではあります。
参考サイト
http://d.hatena.ne.jp/mir/20080407/p1
http://open-groove.net/jmeter/cpu-utilization-monitor/
おまけ
ソーシャルゲーム「AFTER FIRE Re」
チューニングカーやレースがお好きな方であれば、楽しんでいただけるタイトルですので、ぜひプレイしてみてください!
mobage版
http://g12023700.sp.pf.mbga.jp/
